Самообучаемые системы с самомодифицирующимися правилами
Одним из перспективных подходов к разработке самонастраивающейся СУ является методика самомодифицирующихся правил (СМП), описанная в работах Шмидхубера. Методика позволяет реализовать самообучение на основе примитивных алгоритмов обучения в режиме реального времени. При этом, правилами управления называют функцию управляющих воздействий на объект управления, определенную на пространстве состояний среды и состояний объекта. Правилами самообучения называют такие правила управления, которые служат адаптации СУ.
Методика самомодифицирующихся правил
Модифицируемые компоненты самообучаемой СУ называются правилами. Алгоритм, который модифицирует набор правил, называется алгоритмом обучения. Если в таком алгоритме существуют правила, которые изменяют сам набор правил, то мы будем называть это самообучением. Необходимость в таких правилах появляется, когда, накапливая опыт, СУ пытается улучшить свою деятельность. Чтобы заставить набор правил, то есть СМП, производить все лучшее и лучшее изменение самих себя, используется алгоритм истории успеха (АИУ), который в своей основе использует обучение с подкреплением. Во время работы СУ, в моменты времени, вычисленные формулой временных тегов СМП, выполняется алгоритм АИУ. Алгоритм АИУ использует рекурсивный поиск для отмены таких предыдущих СМП-сгенерированных СМП-изменений, которые снижали подкрепление (рассчитанные до текущего вызова АИУ – это оценка долговременных эффектов СМП-изменений, формирующая базу для дальнейших СМП-изменений). СМП-изменения, которые были обработаны алгоритмом АИУ, представляют долговременную историю успеха (далее ДИУ). При следующем вызове АИУ, на базе ДИУ формируются дополнительные СМП-изменения. Благодаря использованию самомодификаций СМП/АИУ - обучаемые СУ успешно выполняют задачи управления в частично наблюдаемых средах (ЧНС).
Методика СМП использует в своем ядре принцип алгоритмического сдвига бритвы Оккама и поиск по Левину.
Под словосочетанием «обучение обучению» будем понимать следующую обучаемую систему, которая:
- оценивает, сравнивает методы обучения и выбирает лучший из них;
- вычисляет оценку «правильности» предыдущего обучения и успешно проецирует его на последующее обучение;
- использует эту оценку для выбора предпочтительной стратегии обучения и отбраковки остальных стратегий.
Методика СПМ не предполагается, как имеющая свойство обучения обучению, если она улучшается только за счет действий выбранных случайным образом, если она не измеряет эффекты раннего обучения и дальнейшего обучения, или если она не имеет явных методов, разработанных для использования подобных измерений для выбора полезных стратегий обучения.
Базовый
алгоритм самомодифицирующихся правил
Рассмотрим базовый алгоритм СМП. Обучаемая система живет от времени 0 до времени T в неизвестной, на момент времени 0, среде E. Система имеет состояние S и первонааотные правила СМП0. S и СМП являются изменяемыми. Между временем 0 и T, обучаемая система повторяет снова и снова следующий цикл (A – возможные действия):
выбрать и выполнить ![]() с наибольшей
возможной вероятностью
с наибольшей
возможной вероятностью![]() . Действие может выполняться некоторое время
. Действие может выполняться некоторое время ![]() [28,30] и может
изменять E, S, и даже сам набор СМП.
[28,30] и может
изменять E, S, и даже сам набор СМП.
Действия в A, которые модифицируют СМП, называются примитивными алгоритмами обучения (ПАО). ПАО и другие действия могут комбинироваться различными способами для формирования более сложных алгоритмов обучения.
Вся жизнь обучаемой системы разбивается на временные интервалы.
Отсечки между интервалами назовем контрольными точками. Контрольные точки
динамически вычисляются в течении жизни системы
определенными действиями из A, выполняемыми в соответствии с самими СМП. ![]() .обозначает
.обозначает ![]() - ю
уонтрольную точку. Для контрольных точек
основополагающими являются следующие правила:
- ю
уонтрольную точку. Для контрольных точек
основополагающими являются следующие правила:
а) ![]()
б) ![]()
в) За исключением первой (время 0), контрольные точки не могут появиться перед тем, как хотя бы один ПАО не будет выполнен после того, как выполнено хотя бы одно СМП-изменение после последней контрольной точки.
![]() обозначает
последовательность СМП-изменений (ПСМ), рассчитанных
ПАО обучения между состояниями
обозначает
последовательность СМП-изменений (ПСМ), рассчитанных
ПАО обучения между состояниями ![]() и
и ![]() . Так как вероятность выполнения ПАО зависит от СМП, СМП
могут, теоретически, изменять способ, которым они изменяют сами себя. Однако, на данный момент данное правило не опубликовано.
. Так как вероятность выполнения ПАО зависит от СМП, СМП
могут, теоретически, изменять способ, которым они изменяют сами себя. Однако, на данный момент данное правило не опубликовано.
Цель системы в ![]() - сгенерировать СМП-изменения, которые ускорят долгосрочное повышение
подкрепления: при этом желательно, чтобы
- сгенерировать СМП-изменения, которые ускорят долгосрочное повышение
подкрепления: при этом желательно, чтобы ![]() превысило текущее
среднее поступление подкрепления. Для того чтобы скорость изменения
подкрепления, необходима предыдущая точка
превысило текущее
среднее поступление подкрепления. Для того чтобы скорость изменения
подкрепления, необходима предыдущая точка ![]() для вычисления
для вычисления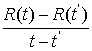 . Множество прошлых контрольных точек, которое используется
для расчета ускорения поступления будующего
подкрепления, обозначим за V. Обозначим через
. Множество прошлых контрольных точек, которое используется
для расчета ускорения поступления будующего
подкрепления, обозначим за V. Обозначим через ![]() -ый элемент множества V. При
этом
-ый элемент множества V. При
этом ![]() отсортированно в порядке
возрастания. Критерий истории успеха (КИУ) удовлетворен для времени t, если или множество V пусто (то есть при старте работы
СУ), или:
отсортированно в порядке
возрастания. Критерий истории успеха (КИУ) удовлетворен для времени t, если или множество V пусто (то есть при старте работы
СУ), или:
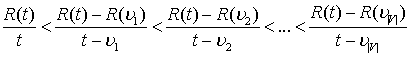 , (1.12)
, (1.12)
КИУ требует, чтобы каждая контрольная точка в V обозначала время начала ускорения поступления долгосрочного подкрепления, взвешенного к текущему моменту времени t. Для каждой контрольной точки мы вызываем алгоритм истории успеха (АИУ):
- пока КИУ не выполняется - отменить все СМП-изменения сделанные со времени самой последней контрольной точки в V. Сделать множество V пустым.
- добавить текущую контрольную точку в V.
«Отмена» изменений означает восстановление предыдущих СМП – это требует сохранения в стеке прошлых значений компонентов СМП перед изменениями. Таким образом, каждое СМП-изменение, которое оставило в действии АИУ, является специфичной частью системы, сгенерированной после обработки контрольной точки и отмечается, как ускоряющая долговременное подкрепление. Между двумя контрольными точками СМП временно защищено от оценок АИУ. Так как способ установки контрольных точек зависит от СМП, СМП могут обучаться выбору контрольных точек, когда необходимо оценивать самих себя. Эта способность важна в случае неопределенных задержек в поступлении подкрепления.
В конце каждого вызова АИУ, пока не произошел следующий,
происходит «временное присвоение». СМП-изменения,
которые «пережили» все предыдущие вызовы АИУ остаются используемыми. При неочевидности обратного, каждая выжившая последовательность
изменений ![]() может являться основой
для дальнейших успешных
может являться основой
для дальнейших успешных ![]() . Так как жизнь системы направлена вперед, то во время
каждого вызова АИУ система должна обобщить знания от одного полученного опыта
относительно правильности изменений правил, выполненных после любого момента
времени.
. Так как жизнь системы направлена вперед, то во время
каждого вызова АИУ система должна обобщить знания от одного полученного опыта
относительно правильности изменений правил, выполненных после любого момента
времени.
К достоинствам методики СМП можно отнести самообучение на основе ПАО и то, что система фактически подстраивается под среду согласно сигналу подкрепления. Таким образом, становится возможной адаптация СУ к изменяемой среде. Так как успех каких-либо СМП-изменений рекурсивно зависит от успеха последующих СМП-изменений, для которых данное является базой, АИУ (отлично от других методов обучения с подкреплением) автоматически предоставляет базис для мета-обучения: АИУ предпочитает такие SSM, которые создают «хорошие» будущие SSM. Другими словами, АИУ предпочитает вероятные алгоритмы обучения, которые приводят к лучшим алгоритмам обучения, что обеспечит при управлении меньшую необходимость в переобучении.
Недостаток СМП при решении задач управления (задач выполняющихся в режиме реального времени) заключается в том, что в алгоритме используются рекурсии, которые замедляют время выполнения задачи. Есть также опасность зацикливания алгоритма, в том смысле, что будет постоянный возврат к наилучшей, с точки зрения системы, контрольной точке, что неприемлемо для полностью автономных систем (таких как автономные роботы). Конечно, в обобщенных средах ни СМП/АИУ, ни любая другая схема не гарантируют нахождения «оптимальных» правил управления, которые приведут к максимальному накопительному подкреплению. АИУ гарантирует только выборочную отмену таких изменений правил, которые, из эмпирических наблюдений, не привели к сильному повышению среднего поступления подкрепления.
Таким образом, для задач управления объектами в недетерминированных средах, необходимо использовать усовершенствованную методику СМП. Для этого мы будем использовать набор СМП разбитый на два под-набора: реактивные, то есть тактические и про – активные, то есть стратегические правила. Это позволит более детально прорабатывать правила обучения, что в свою очередь, позволит строить более качественные СУ. При этом верхняя, стратегическая составляющая будет фактически одинакова под различные СУ.