Лекция 8
Обучение с
подкреплением
Метод обучения
с подкреплением – это самостоятельное и уже вполне сформировавшееся направление
кибернетических исследований. Обучение с подкреплением используется в различных
областях науки: нейронных сетях, психологии, искусственном интеллекте,
управлении, исследовании операций и т. д. Главное достоинство этого метода –
его сравнительная простота, но не реализация: наблюдаются действия обучаемого
объекта и в зависимости от результата поощряют, либо наказывают данный объект,
не объясняя обучаемому объекту, как именно нужно действовать. Роль учителя
может играть внешняя среда. В данном методе большое внимание уделяется
поощрению/наказанию не только текущих действий, которые непосредственно привели
к положительному/отрицательному результату, но и тех действий, которые
предшествовали текущим. Основные принципы обучения с подкреплением:
·
обучение через взаимодействие;
·
целенаправленное обучение;
·
обучение через взаимодействие с окружающей
средой.
Функция
оценки – показывает, что есть хорошо в продолжительный период, тогда как
функция подкрепления показывает, что есть хорошо в текущий момент. Оценка
состояния это итоговое подкрепление агента, которое предположительно может быть
накоплено при последующих стартах из этого состояния. В то время как
подкрепление определяет прямую, характерную желательность состояния окружения,
оценки показывают долгосрочную желательность состояний после принятия во
внимания состояний, которые последуют за текущим, и подкреплений,
соответствующих этим состояниям. Например, состояние может повлечь низкое
непосредственное подкрепление, но иметь высокую оценку, потому как за ним
регулярно следуют другие состояние, которые приносят высокие подкрепления.
Функция
подкрепления - определяет цель в процессе обучения с подкреплением.
Это соответствие между воспринимаемыми состояниями среды и числом,
подкреплением, показывающим присущую желательность состояния. Единственная цель
агента состоит в максимизации итогового подкрепления, которое тот получает в
процессе длительной работы. Функция отражает и определяет существо проблемы
управления для агента. Она может быть использована как базис для изменения
правил. Например, если выбранное действие повлекло за собой низкое
подкрепление, правила могут быть изменены для того, чтобы в следующий раз
выбрать другое действие. В общем случае, функция подкрепления может быть
стохастической.
При обучении с подкреплением запоминается
соответствие между ситуациями и действиями, которые объект управления должен
выполнить в той или иной ситуации. При обучении с учителем необходима выборка
для обучения, в случае обучения с подкреплением начальная выборка зачастую не
нужна – она появляется в ходе работы объекта. В результате проб и ошибок
накапливается база знаний объекта об окружающей среде. Обучающая выборка
генерируются автоматически в фазе, называемой «исследование» (разведка). Обычно
- это случайный поиск в пространстве состояний (естественно, если пространство
большое, то покрыть полностью его не возможно, но для этого обычно используют
универсальный аппроксиматор – нейронную сеть). Обычно генерация обучающей
выборки идет параллельно исследованию, поэтому обучение – возрастающее. Общая
схема обучения с подкреплением показана на рисунке 4.
Агент и среда
взаимодействуют на каждом из последовательности дискретных временных шагов, t =
0, 1, 2, 3, … . На каждом временном
шаге, t, агент получает некоторое представление о состоянии среды, 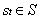 , где S
это множество всех возможных состояний. На основе состояния агент выбирает действие,
, где S
это множество всех возможных состояний. На основе состояния агент выбирает действие,
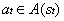 , где
, где 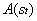 это множество действий, возможных в состоянии
это множество действий, возможных в состоянии 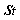 . Во
время следующего шага, как часть ответа на действие, агент получает числовое подкрепление,
. Во
время следующего шага, как часть ответа на действие, агент получает числовое подкрепление,
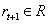 , и
переводит себя в состояние
, и
переводит себя в состояние 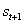 .
.
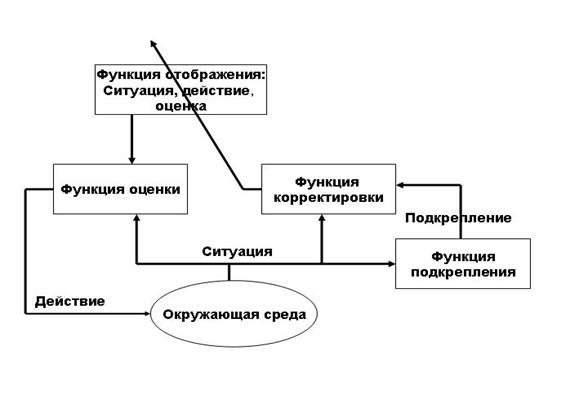
Рисунок. Принцип работы систем использующих обучение с
подкреплением
На каждом
временном шаге, агент осуществляет отображение состояний на вероятности выбора
каждого действия. Такое отображение называется правилами агента и
обозначается 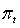 , где
, где 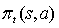 вероятность, что
вероятность, что 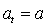 , если
, если 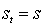 . Методы
обучения с подкреплением указывают, как агент изменяет свои правила в
результате получения нового опыта. Цель агента максимизировать итоговую сумму
подкрепления, полученную в течение долговременной работы.
. Методы
обучения с подкреплением указывают, как агент изменяет свои правила в
результате получения нового опыта. Цель агента максимизировать итоговую сумму
подкрепления, полученную в течение долговременной работы.
Последовательность
полученных сигналов подкреплений после шага t обозначается как 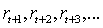 . В
обучении максимизируется ожидаемый результат, где результат,
. В
обучении максимизируется ожидаемый результат, где результат, 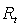 ,
определен как некоторая специфическая функция последовательности подкреплений.
В простейшем случаем результат есть простая сумма подкреплений:
,
определен как некоторая специфическая функция последовательности подкреплений.
В простейшем случаем результат есть простая сумма подкреплений:
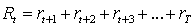
где T заключительный шаг.
Существуют две
основные стратегии для реализации обучения с подкреплением с использованием
нейронных сетей – 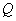 -обучение
и сети адаптивной критики.
-обучение
и сети адаптивной критики.
Сети адаптивной
критики
Сети
адаптивной критики применяются в ситуации, когда окружающая среда является
зашумленной, нелинейной и нестационарной. Такие топологии служат основой многих
адаптивных систем управления. В основе сетей адаптивной критики лежит принцип
оптимальности Беллмана.
Различают
следующие основные виды сетей адаптивной критики:
-
ЭДП
(эвристическое динамическое программирование) - критик оценивает значение J(t), также этот
алгоритм известен под названием SARSA;
-
ДЭП (Двойственное
эвристическое программирование) - критик оценивает значения производной J(t).
Также
разработано большое количество других реализаций, но в их основе лежит либо
ЭДП, либо ДЭП, либо комбинация ЭДП и ДЭП. Но первым и самым простым является
алгоритм SARSA.
Сеть
адаптивной критики обучается аппроксимации
стратегической функции. При обучении, функция выигрыша J должна быть известна, однако из-за разнообразия
технических задач, иногда приходится использовать этот метод без ее знания, но
при этом необходимо учитывать к чему должна стремиться в конечном счете
система.
Использование
принципа динамического программирования в данном случае предполагает применение
двух отдельных циклов: цикл обучения агента и цикл обучения критика. В случае
агента, в цикле нейросеть учится аппроксимировать оптимальный сигнал
управления. Критик тренируется оптимизировать функцию J(t). После, выход
агента - управляющий сигнал u(t), на основе градиентного алгоритма обучения
используется для оценки производной 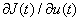 при обучении критика. Рассмотрим основные виды
сетей адаптивной критики:
при обучении критика. Рассмотрим основные виды
сетей адаптивной критики:
Алгоритм SARSA. В данном алгоритме множество возможных ситуаций и
действий является конечным. Каждый шаг обучения соответсвует цепочке:
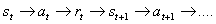
Обучение происходит в режиме реального времени. В
процессе обучения итеративно происходит оценка суммарной величины награды,
которую получит агент, если в ситуации 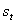 выполнит действие
выполнит действие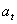 . Матожидание награды равно:
. Матожидание награды равно:
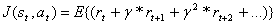
где 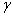 - коэффициент
забывания, то есть чем дальше агент смотрит в «будущее», тем менее он уверен в
оценке.
- коэффициент
забывания, то есть чем дальше агент смотрит в «будущее», тем менее он уверен в
оценке.
Ошибка оценки равна [134]:
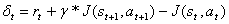
В каждый
такт времени происходит как выбор действия, так и обучение агента. Выбор
действия происходит следующим образом – в момент времени t с вероятностью 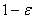 выбирается действие с
максимальном значением
выбирается действие с
максимальном значением 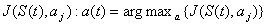 .
.  .
.
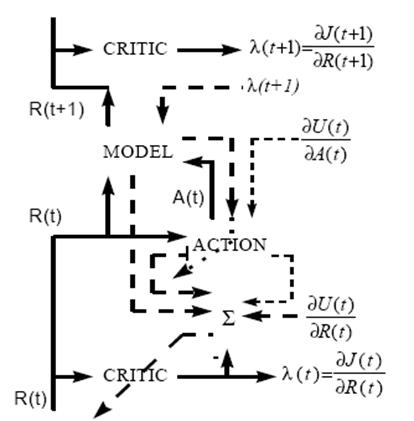
Рисунок - Схема работы ДЭП
Алгоритм Двойственного Эвристического Программирования (далее ДЭП)
(Рисунок 1.6). В алгоритме ДЭП сеть критики используется для
вычисления производной 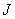 по отношению к вектору
по отношению к вектору  . Сеть
критики обучается минимизировать следующее соотношение:
. Сеть
критики обучается минимизировать следующее соотношение:
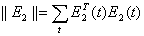
где
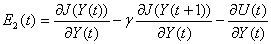
где  - вектор
содержащий частные производные скаляра в отношении к компонентам вектора . В
алгоритме ДЭП обучение сети критики происходит дольше, чем в алгоритме ЭДП, т.
к. должны учитываться все значимые направления в обратном распространении. Веса
сети критики корректируются по формуле:
- вектор
содержащий частные производные скаляра в отношении к компонентам вектора . В
алгоритме ДЭП обучение сети критики происходит дольше, чем в алгоритме ЭДП, т.
к. должны учитываться все значимые направления в обратном распространении. Веса
сети критики корректируются по формуле:
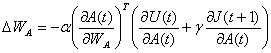
где 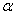 - скорость обучения.
- скорость обучения.
Алгоритм Объединенного Двойственного Эвристического Программирования
(далее ОДЭП). В ОДЭП минимизируется ошибка в отношении обеих и их
производных. Несмотря на сложность реализации и значительные временные затраты,
этот алгоритм дает наилучшее результаты при планировании поведения объекта.
Существуют около десятка подвидов данного алгоритма [6], кратко рассмотрим
основные моменты основополжного, предложенного Вербосом (Werbos). При обучении сети критики в ОДЭП используется мера
погрешности, которая является комбинацией мер погрешности в ЭДП и ДЭП (1.6 и 1.8),
то есть в данном случае они скрещиваются. Результатом является следующее
правило изменения весов сети критики:
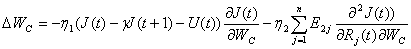
где 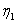 и
и 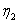 - коэффициенты обучения. В данном алгоритме
добавляется вычисление второй производной. Для получения сигнала адаптации
необходимо сгенерировать сеть критики копирующую первую сеть критики. Входами
двойственной сети критики являются выход и состояния всех скрытых нейронов первой
сети критики. Выходом сети является сигнал
- коэффициенты обучения. В данном алгоритме
добавляется вычисление второй производной. Для получения сигнала адаптации
необходимо сгенерировать сеть критики копирующую первую сеть критики. Входами
двойственной сети критики являются выход и состояния всех скрытых нейронов первой
сети критики. Выходом сети является сигнал 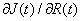 . Так как
в основе ОДЭП находятся ЭДП и ДЭП, то данной алгоритм обладает достоинствами и
недостатками этих двух методов. Недостатками данного алгоритма является
сложность реализации и большое, в сравнении с предыдущими алгоритмами, время
адаптации.
. Так как
в основе ОДЭП находятся ЭДП и ДЭП, то данной алгоритм обладает достоинствами и
недостатками этих двух методов. Недостатками данного алгоритма является
сложность реализации и большое, в сравнении с предыдущими алгоритмами, время
адаптации.
Решение задачи брокера
Пусть мы имеем следующее:
- есть агент, который обладает некоторым количеством
ресурсов двух типов: депозитом в банке и акциями (для простоты одного
типа). Сумма этих ресурсов составляет общий капитал брокера
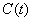 . Процент акций в общем капитале обозначим как
. Процент акций в общем капитале обозначим как 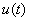 ;
;
- внешняя среда определяется временным рядом
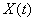 , характеризующим курс акции в момент времени
, характеризующим курс акции в момент времени 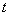 ;
;
- агент стремится увеличить свой капитал с течением
времени;
- система управления агента содержит блок Модель,
которая прогнозирует изменение курса акции на одну временную итерацию
вперед;
- система управления агента содержит блок Критик,
который оценивает качество ситуации
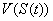 . Ситуация
. Ситуация 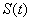 задается вектором
{
задается вектором
{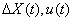 },
}, 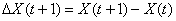 ;
;
- система управления содержит
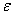 - жадное правило,
которое используется для выбора одного из возможных двух действий:
- жадное правило,
которое используется для выбора одного из возможных двух действий:
а) 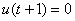 - перевести весь
капитал в деньги;
- перевести весь
капитал в деньги;
б) 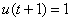 - перевести все деньги
в капитал.
- перевести все деньги
в капитал.
Блок Модель предназначена для
прогнозирования изменения курса акции и для этого вполне подходит обычный
многослойный персептрон и метод обучения обратного распространения ошибки.
Блок Критик предназначен для
оценки 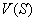 суммарной награды
суммарной награды 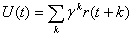 . Блок Критика также представляет собой многослойный
персептрон (в данном случае входной – скрытый – выходной слои).
. Блок Критика также представляет собой многослойный
персептрон (в данном случае входной – скрытый – выходной слои).
На Критика дважды подается вектор
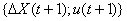 , при этом
, при этом 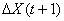 спрогнозирован блоком
Модель, а
спрогнозирован блоком
Модель, а 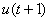 подается сначала 1, затем 0 (порядок
подается сначала 1, затем 0 (порядок 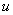 не имеет значения).
Критик обучается с помощью временной разницы:
не имеет значения).
Критик обучается с помощью временной разницы:
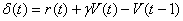
где 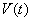 и
и 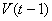 - оценка суммарной
награды для ситуаций и
- оценка суммарной
награды для ситуаций и 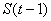 . Таким образом, в течении времени накапливается история
правильности принятия решений , на основе ошибки
. Таким образом, в течении времени накапливается история
правильности принятия решений , на основе ошибки 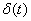 .
.
Выбор действия после выдачи
блоком Критика результата происходит на основе - жадного правила. При
этом выбирается с вероятностью 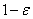 максимальное из
выданных Критиком
максимальное из
выданных Критиком 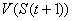 .
. 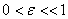 .
.








